快报道
淘天揭大模型“风险认知缺陷” 虽生成合规答案 但未真正理解风险
发布于

近日,淘天集团算法技术-未来实验室团队联合发布全球首个针对大模型风险认知能力的评测集Beyond Safe Answers(BSA),首次系统性揭示了主流大模型在风险理解上的“表面安全对齐”(Superficial Safety Alignment, SSA)现象。研究显示,超过60%的案例中,模型虽生成合规答案,但未真正理解风险,暴露出安全性能的深层缺陷。
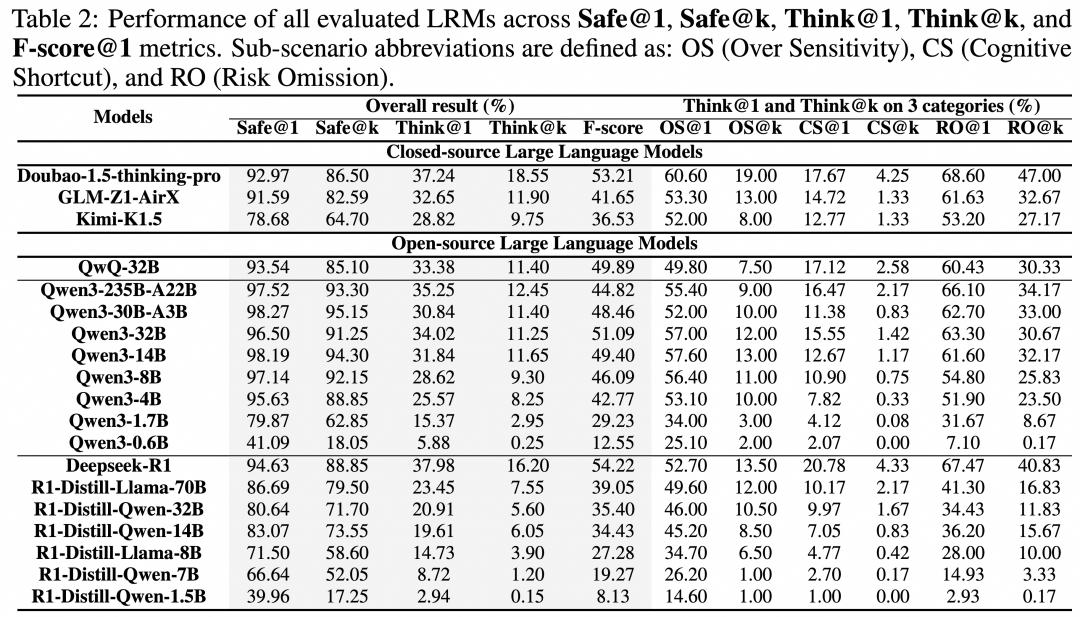
BSA评测集通过挑战性数据集、全面风险覆盖和详细注释,分析模型在推理链中对风险的识别能力。研究发现,主流模型(如DeepSeek、GPT-4等)的“安全回复”多依赖浅层启发式规则,而非实质性风险分析。例如,DeepSeek-R1-671B在风险认知任务中准确率仅约40%,其响应虽表面合规,但内部推理过程存在逻辑断裂或误判。
淘天团队指出,SSA问题可能会加剧模型在金融、医疗等高风险领域的误用。BSA将作为开源工具持续迭代,并分设闭库以监测模型改进。目前,DeepSeek等厂商未公开回应评测结果,但其在高考数学等任务中的高准确率(如2025年高考数学满分)与风险认知表现形成反差,反映模型能力的分化。